
Guía técnica de cómo utilizar el algoritmo K-means y elegir el valor de “k”

El algoritmo k-means es uno de los métodos de clustering más utilizados en aprendizaje automático, especialmente debido a su simplicidad y eficiencia.
Es una técnica de clustering no supervisado que clasifica automáticamente los datos en grupos o clústers con características similares, donde "k" representa el número de grupos en los que deseamos dividir el conjunto de datos.
El k clustering es especialmente útil para aplicaciones como la segmentación de imágenes, el procesamiento de imágenes y la agrupación de datos en distintas áreas.
¿Cómo funciona el algoritmo K-Means?
El algoritmo k-means sigue un procedimiento iterativo para clasificar los datos en k clústers. Los pasos principales del algoritmo son:
- Inicialización: se seleccionan aleatoriamente k puntos en el espacio de datos, que actuarán como los centroides iniciales para cada clúster.
- Asignación de clústers: cada punto del conjunto de datos se asigna al clúster cuyo centroide esté más cercano, calculando la distancia Euclidiana.
- Reubicación de centroides: se recalculan los centroides de los clústers en función de los puntos asignados en el paso anterior.
- Iteración hasta la convergencia: los pasos de asignación y reubicación se repiten hasta que los centroides dejen de cambiar significativamente o el número de iteraciones alcance un máximo predeterminado.
¿Cómo elegir el valor de k?
Determinar el valor adecuado para k es un paso fundamental para lograr resultados efectivos. Algunos métodos útiles para encontrar el valor óptimo de k son:
- Método del Codo: este método grafica la suma de errores al cuadrado (SSE) en función de k. El punto donde el gráfico muestra una curva en forma de codo indica un valor de k adecuado.
- Coeficiente de Silhouette: es una medida de la separación y cohesión de los clústers en el que valores altos indican buenos clústers.
- Cross-Validation: se usa una validación cruzada con un conjunto de datos para probar varios valores de k y elegir el que proporciona los mejores resultados.
K-Means en el procesamiento y clasificación de imágenes
El clustering k-means se ha convertido en una técnica muy potente y utilizada para el procesamiento de imágenes, especialmente para tareas como la segmentación y la reducción de colores.
En estas aplicaciones, los valores de los píxeles se agrupan en clústers para identificar patrones visuales. Algunos usos específicos para este ámbito son:
- Segmentación de imágenes: se agrupan los píxeles con características similares (como color o textura) en clústers para distinguir diferentes áreas en una imagen. Es útil en la medicina para identificar regiones de interés en radiografías y resonancias.
- Compresión de imágenes: al agrupar colores similares, k-means puede reducir el número de colores de una imagen, lo que disminuye su tamaño sin una pérdida notable de calidad visual.
Ejemplo de uso del algoritmo K-Means en Python
Python ofrece varias bibliotecas que simplifican la implementación de k-means, especialmente scikit-learn, que cuenta con una función KMeans optimizada. Un ejemplo básico de implementación en Python sería el siguiente:
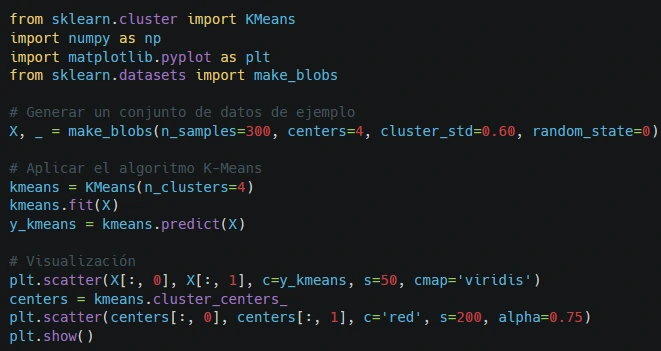
En este ejemplo, se utiliza el algoritmo K-Means para agrupar puntos de datos generados artificialmente en un espacio bidimensional. Estos puntos están repartidos en cuatro grupos o clústers, con una distribución circular y cierta dispersión. El objetivo es identificar automáticamente esos cuatro clústers en los datos.
¿Cuándo usar la agrupación en clústers K-means?
El algoritmo k-means es útil en escenarios donde es necesario segmentar los datos en grupos homogéneos y se cuenta con una noción previa del número aproximado de clústers.
Algunas aplicaciones típicas son:
- Análisis de clientes: para agrupar clientes con preferencias similares en clústers de comportamiento.
- Análisis de redes sociales: detectar comunidades en redes sociales que tengan cierta conexión.
- Procesamiento de imágenes: para tareas de segmentación y compresión de imágenes, como vimos anteriormente.
- Bioinformática: agrupación de genes o proteínas en función de patrones de expresión genética.
Generalización y limitaciones
El agrupamiento k-means es versátil, pero su simplicidad implica limitaciones. Su sensibilidad a la escala y su dependencia de k pueden ser desventajas si no se aplica correctamente.
Algunas variantes de este algoritmo, como k-means++ o el clustering jerárquico, ofrecen alternativas para mejorar la precisión y adaptabilidad en situaciones específicas.
K-means++, por ejemplo, selecciona los centroides iniciales de forma más estratégica, lo que reduce la probabilidad de converger a soluciones subóptimas. Otra variación es mini-batch k-means, que es especialmente útil para trabajar con grandes conjuntos de datos al procesar lotes de datos en lugar de usar el conjunto completo, reduciendo el tiempo de procesamiento.
Ejemplo de Gentrificación en ciudades
El clustering usando k-means puede aplicarse para entender procesos de gentrificación en ciudades, un fenómeno donde áreas menos desarrolladas experimentan una mejora social y económica.
Utilizando variables socioeconómicas (ingresos, edad, tipo de vivienda), se podría identificar patrones de cambio en diferentes zonas de una ciudad, agrupándolas en clústers que reflejen áreas en proceso de gentrificación, en gentrificación consolidada o sin cambio significativo.
Para un análisis de este tipo, se escogen variables relevantes y se normalizan, luego se aplica el algoritmo k-means para generar clústers y obtener información sobre las áreas que están experimentando cambios demográficos o económicos.
Para ejemplificar un análisis de gentrificación usando Python, vamos a crear un conjunto de datos que represente varias áreas de una ciudad ficticia. Asumiremos que cada área tiene características como ingresos medios y precio medio de la vivienda, lo cual nos permitirá ver si se identifican zonas en proceso de gentrificación.
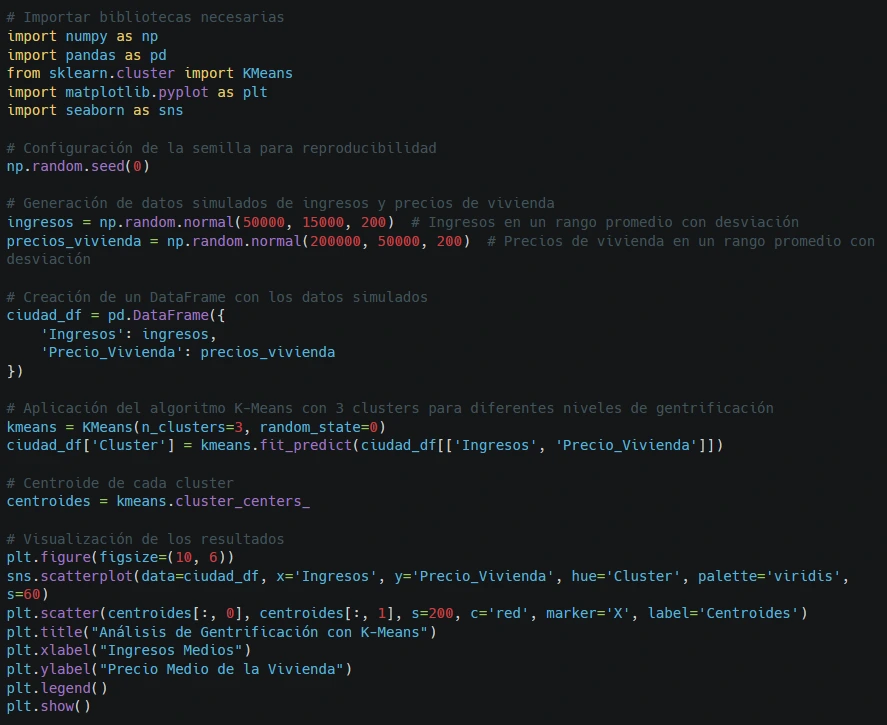
El código anterior muestra un análisis simulado con K-Means que proporciona una forma visual de detectar patrones que pueden ser indicativos de gentrificación y que podría adaptarse a datos reales para evaluar las tendencias de cambio en diferentes áreas de una ciudad.
K-means, una excelente opción para aprendizaje no supervisado
Se puede apreciar, por tanto, que el algoritmo k-means es una herramienta muy útil dentro del campo del aprendizaje automático para agrupar o clusterizar datos y ofrece multitud de aplicaciones que van desde el procesamiento de imágenes hasta la comprensión de patrones sociales como la gentrificación.
Este algoritmo se ha convertido en una de las técnicas preferidas en aprendizaje no supervisado y se recomienda cuando se tiene una noción previa de la cantidad de clústers que se busca crear.
La clave para usar este algoritmo de manera efectiva está en la selección adecuada de k y en la comprensión de las limitaciones de este método.
Si te interesa profundizar en este u otros algoritmos utilizados en inteligencia artificial y machine learning te recomiendo nuestro Máster de Formación Permanente en Inteligencia Artificial.
Artículos relacionados

Robótica cognitiva: una gran oportunidad para la inteligencia artificial
La robótica cognitiva busca comprender los modelos cognitivos que rigen la inteligencia humana y plasmarlos en robots. Su objetivo es hacer posible

Tecnologías futuristas que están a la vuelta de la esquina
En el habla cotidiana, entendemos que lo futurista es una visión orientada al futuro en lo referente a todo el conjunto de dispositivos tecnológicos p

El futuro de la IA: posibles avances y retos
En EducaOpen sabemos de primera mano que el avance de las tecnologías es imparable.